The Do's and Don’ts of Java Strings
今天,我们将要讨论Java中的字符串。 如果您经常编写Java,您会知道String被认为是第一类对象,即使它不是八种基本类型之一。 您可能不知道的是如何在生产应用程序中最好地处理字符串。 为此,您需要了解如何对String进行国际化/本地化,如何处理非常大的String或深入了解String比较规则。 所以,让我们开始...
何时以及如何国际化/本地化Java字符串
国际化(i18n)是提供不同语言的人类可读字符串的过程,而本地化(l10n)则需要进一步考虑地理和文化因素。 国际化是过程,而本地化是精细的。 例如,字符串"选择您喜欢的颜色"和"选择您喜欢的颜色"都是英文(i18n),但前者在美国(en-US)使用,而后者在英国(en-GB)使用 )。 (这些代码在RFC 5646中概述的"用于标识语言的标记"中定义。)
除标准消息传递外,i18n / l10n在表示日期/时间和货币时也非常重要。 将字符串翻译成更长的语言(例如德语)的结果可能导致甚至最精心计划的UI都被完全重新设计,而增加对双字节字符集(即中文,日文,韩文)的支持通常可能需要在整个过程中进行有意义的更改 整个堆栈。
就是说,显然不必翻译应用程序中的每个String -只需人类会看到的即可。 例如,如果您有一个用Java编写的服务器端RESTful API,则可以:a)在请求中查找Accept-Language标头,根据需要应用设置,然后返回本地化的响应,或者b)返回通常不变的响应, 返回错误代码的错误情况除外(前端然后使用该错误情况来查找翻译后的String并显示给用户)。 如果前端已知且在您的控制范围内,则选择b。 您可以选择是否将原始响应(甚至是错误响应)整体呈现给用户,或者您的API是否可供未知的使用者使用,并且不确定如何使用响应。
直接将Strings直接呈现给可能不会说英语的人的Java应用程序当然需要进行翻译。 再次考虑要求用户输入他或她喜欢的颜色的示例:
1 2 3 4 5 6 7 8 9 10 | public class Main { public static void main(String[] args) throws IOException { Interviewer interviewer = new Interviewer(); System.out.println(interviewer.askColorQuestion()); Scanner scanner = new Scanner(System.in); String color = scanner.nextLine(); System.out.println(interviewer.respondToColor(color)); scanner.close(); } } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | class Interviewer { String askColorQuestion() { return"Enter your favorite color:"; } String respondToColor(String color) { //You can switch on Strings since Java 7 switch (color) { case"red": return"Roses are red"; case"blue": return"Violets are blue"; case"yellow": return"Java is awesome"; default: return"And so are you"; } } } |
我使用的Java IDE Eclipse提供了一种从Interviewer类提取字符串的好方法。
…并将它们放入.properties文件中,我将其调整为如下所示:
1 2 3 4 5 6 7 8 | Interviewer.color.question=Enter your favorite color: Interviewer.color.definition.1=red Interviewer.color.definition.2=blue Interviewer.color.definition.3=yellow Interviewer.color.response.1=Roses are red Interviewer.color.response.2=Violets are blue Interviewer.color.response.3=Java is awesome Interviewer.color.response.default=And so are you |
不幸的是,就switch语句而言,此过程使Strings不再恒定。
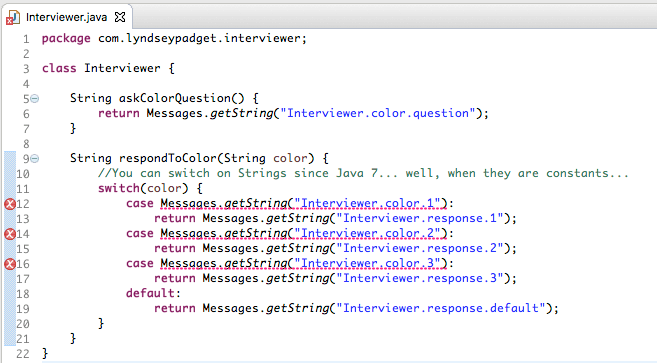
这有点不幸,但也为我们提供了一个机会,可以预期此应用程序在将来的某个时候可能需要处理不止三种颜色。 在Eclipse为我创建的Messages类中,我添加了一个方法,该方法将返回给定前缀的任何键/值对:
1 2 3 4 5 6 7 8 9 10 11 | public static Map < String, String > getStrings(String prefix) { Map < String, String > retVal = new HashMap < String, String > (); Enumeration < String > keys = RESOURCE_BUNDLE.getKeys(); while (keys.hasMoreElements()) { String key = keys.nextElement(); if (key.startsWith(prefix)) { retVal.put(key, RESOURCE_BUNDLE.getString(key)); } } return retVal; } |
并且Interviewer类使用它来更动态地查找用户的响应并对其进行操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class Interviewer { String askColorQuestion() { return Messages.getString("Interviewer.color.question"); } String respondToColor(String color) { Map < String, String > colorMap = Messages.getStrings("Interviewer.color.definition."); for (String colorKey: colorMap.keySet()) { String colorValue = colorMap.get(colorKey); if (colorValue.equalsIgnoreCase(color)) { String responseKey = colorKey.replace("definition","response"); return Messages.getString(responseKey); } } return Messages.getString("Interviewer.color.response.default"); } } |
结果是可以轻松地翻译该应用程序。 根据某些条件(例如环境变量或用户请求),您可以使用Java的ResourceBundle加载另一个提供特定于区域设置的消息的属性文件。
串联还是不串联?
假设我们要在系统的响应中考虑用户喜欢的颜色,以便告诉用户:"哦,是的,____也是我喜欢的颜色!" 您可以将其分为两个字符串:"哦,是的"和"也是我最喜欢的颜色!"。 结果看起来像这样:
1 2 | Interviewer.color.response.part1=Oh yes, Interviewer.color.response.part2=is also my favorite color! |
1 2 3 4 5 |
但这对i18n / l10n来说是个坏消息,因为不同的语言通常会重新排列名词,动词和形容词的顺序。 消息的某些部分可能会有所不同,具体取决于名词的性别,所讨论的[过去/现在/将来]时态或接收消息的人。 最好保持消息连续且简洁,仅在需要时才替换值。 您可以使用String的替换函数之一,但String.format实际上是用于此目的的:
1 | Interviewer.color.response=Oh yes, %1$s is also my favorite color! |
1 2 3 4 |
当用于构建供计算机使用的小型String时,串联非常好。 构建真正的大弦? 您还将需要比连接更好的东西。
构建真正非常大的字符串
字符串在Java中是不可变的,这意味着它们的值永远不会真正改变。 当您阅读以下代码时,情况似乎并非如此:
1 2 |
但是,您必须记住,第二个分配实际上创建了一个新的String(值" green"),并将该值重新分配了favoriteColor(引用)。 旧的String(值" red")是孤立的,最终将被垃圾回收。
这就是为什么将Strings多次串联是一个坏主意的原因。 每次连接时,应用程序都会隐式创建一个新的String。 让我们看一个示例,在该示例中我们要读取一个名为" colorNames.dat"的HTML颜色的长文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | AliceBlue AntiqueWhite AntiqueWhite1 AntiqueWhite2 AntiqueWhite3 AntiqueWhite4 aquamarine1 aquamarine2 aquamarine4 azure1 azure2 azure3 azure4 beige bisque1 ... |
ColorList类读取此文件的每一行,并创建一个长字符串,其中包含换行符。
1 2 3 4 5 6 7 8 9 10 11 12 | class ColorList { String getAllColors(String filename) throws FileNotFoundException, IOException { String retVal =""; BufferedReader br = new BufferedReader(new InputStreamReader(this.getClass().getResourceAsStream(filename))); for (String line; (line = br.readLine()) != null;) { retVal += line +" "; } return retVal; } } |
请注意,for循环内部的行实际上是在创建四个新字符串:一个用于该行的内容,一个用于换行符,一个将二者结合在一起,以及一个将字符串附加到后面的字符串。 retVal的当前内容。 更糟糕的是,retVal的旧内容随后被丢弃,并替换为新的String。 没有布宜诺斯艾利斯!
解决此类问题的方法是使用StringBuffer –或更新的类似名称的StringBuilder。 两者都将自己定义为"可变的字符序列",从而解决了不变性问题。 StringBuffer从Java 1.0开始就存在并且是线程安全的,这意味着共享"一致且不变的源视图"的线程可以安全地访问StringBuffer对象并对其进行操作。 为了使事情简单,并且通常使性能更高,文档建议改用StringBuilder。
在Java 1.5中引入的StringBuilder具有与其前身相同的接口,但是它不是线程安全的,因为它不能保证同步。 假设您要尝试从一个单一来源(例如文件或数据库)构建一个非常大的String,通常就足以将该作业分配给一个线程并退出。 StringBuilder非常适合该工作,并且我们可以在以下情况下更喜欢使用StringBuffer而不是StringBuffer:
1 2 3 4 5 6 7 8 9 10 11 12 13 | class ColorList { String getAllColors(String filename) throws FileNotFoundException, IOException { StringBuilder retVal = new StringBuilder(); BufferedReader br = new BufferedReader(new InputStreamReader(this.getClass().getResourceAsStream(filename))); for (String line; (line = br.readLine()) != null;) { retVal.append(line); retVal.append(" "); } return retVal.toString(); } } |
如果我们将colorNames.dat文件中的行数提高到大约122,000,然后从main方法中比较concatenate和StringBuilder方法:
1 2 3 4 5 6 7 8 9 10 | public class Main { public static void main(String[] args) throws IOException { long startTime = System.nanoTime(); ColorList colorList = new ColorList(); String allColorNames = colorList.getAllColors("colorNames.dat"); System.out.print(allColorNames); long endTime = System.nanoTime(); System.out.println("Took" + (endTime - startTime) +" ns"); } } |
我们看到,连接方法大约需要50秒才能执行,而StringBuilder方法大约需要0.7秒。 这样可以节省性能 huuuuge !
这是一个简单易测的示例。 如果您希望解决整个应用程序的性能问题,请查看一些针对Java应用程序的更强大的性能工具。
字符串相等
现在我们已经讨论了String值和引用,您将回想起经典的Java知识:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | public class Main { public static void main(String[] args) throws IOException { String s1 ="red"; String s2 ="red"; if (s1.equals(s2)) { System.out.println("s1 and s2 have equal values"); } if (s1 == s2) { System.out.println("s1 and s2 have equal references"); } System.out.println(""); String s3 ="green"; String s4 = new String("green"); if (s3.equals(s4)) { System.out.println("s3 and s4 have equal values"); } if (s3 == s4) { System.out.println("s3 and s4 have equal references"); } System.out.println(" Done!"); } }; |
运行此结果:
1 2 3 4 | s1 and s2 have equal values s1 and s2 have equal references s3 and s4 have equal values Done! |
尽管s1和s2是不同的变量,但是Java(为了有效和有帮助)意识到s2包含与s1相同的值,因此将其指向内存中的相同位置。 这就是为什么它认为它们是相同的参考。 相比之下,s4与s3具有相同的值,但是为该值显式分配了一个在内存中的新位置。 当需要查看它们是否具有相同的参考时,我们看到它们没有相同的参考。
Java如何管理其Strings的引用通常最好由编译器来决定,但是我们仍然必须意识到这一点。 这就是为什么当我们关心两个字符串的各自值时,必须始终使用.equals,要记住搜索或排序字符串的算法也将依赖于此方法。
比较字符串
考虑以下示例,其中包含两个字符串,其值应该用法语表示"深蓝色":
1 2 3 4 5 6 7 8 9 10 11 |
.equals方法逐个字符进行比较,并注意到s1和s2由于大小写而不相等。 String类提供了一种方便的方法,称为.equalsIgnoreCase,我们可以使用该方法忽略差异。 但是,当我们意识到最后一个字符实际上应该带有重音(法语中的正确字词是"foncé"),但是我们希望继续接受旧值并将它们视为相等时,会发生什么?
1 2 3 4 5 6 7 8 9 10 11 |
同样,由于重音符号和空格,这些字符串并不完全相等。 在这种情况下,我们需要指定一种将字符串与比较器进行比较的方法。
DIY比较器
当您想在比较字符串之前以某种方式对字符串进行规范化时,比较器特别有用,但是您不希望该逻辑在整个代码中乱七八糟。
首先,我们创建一个实现Comparator的类,该类为相等逻辑提供了一个不错的家。 这个特殊的Comparator会执行默认String Comparator会做的所有事情,除了它会修剪String并以不区分大小写的方式比较它们。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | public class CloseEnoughComparator implements Comparator < String > { public int compare(String obj1, String obj2) { if (obj1 == null) { return -1; } if (obj2 == null) { return 1; } if (obj1.equals(obj2)) { return 0; } String s1 = obj1.trim(); String s2 = obj2.trim(); return s1.compareToIgnoreCase(s2); } } |
然后,我们更改主要方法以使用比较器:
1 2 3 4 5 6 7 8 9 10 11 12 | public class Main { public static void main(String[] args) throws IOException { String s1 ="bleu fonce"; String s2 ="Bleu foncé "; Comparator < String > comparator = new CloseEnoughComparator(); if (comparator.compare(s1, s2) == 0) { System.out.println("s1 and s2 have equal values"); } else { System.out.println("s1 and s2 do NOT have equal values"); } } }; |
仅剩下一个问题。 由于带有重音符,因此运行上面的代码仍然不能认为这两个字符串相等。 这就是排序规则的来源。
整理的力量
排序是在给定特定规则集的情况下确定顺序(从而确定是否相等)的过程。 您可能听说过数据库上下文中使用的术语归类,那里可能有一个设置来为其中的字符串,金额或日期建立默认归类。
在Java中,Collator是实现Comparator的抽象类。 这意味着我们可以用main方法替换Comparator代码,但是我选择保持该接口不变,并改为更改compare方法的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public class CloseEnoughComparator implements Comparator < String > { public int compare(String obj1, String obj2) { if (obj1 == null) { return -1; } if (obj2 == null) { return 1; } if (obj1.equals(obj2)) { return 0; } Collator usCollator = Collator.getInstance(Locale.US); usCollator.setStrength(Collator.PRIMARY); return usCollator.compare(obj1, obj2); } } |
这里有一些值得注意的变化:
.trim和.compareToIgnoreCase已被删除
我出于说明目的对语言环境进行了硬编码–通常,这将基于某些条件(例如环境变量或用户请求)
整理器的强度设置为"主要"
强度部分很重要。 整理器提供了四种优势供您选择:主要,次要,高等教育和同等。 PRIMARY强度表示可以同时忽略空格和大小写,并且出于比较目的,也可以忽略e和é之间的差异。 尝试使用不同的语言环境和优势,以了解有关整理工作原理的更多信息,或者查看Oracle的国际化教程以获取有关语言环境,整理器,Unicode等的演练。
在Java中,很容易将String视为理所当然,因为我们想做的任何事情都是"可行的"。 但是它可以工作吗……更好? 快点? 世界各地? 答案是肯定的,是的,是的! 只需做一点点试验就可以更彻底地了解Strings的工作原理。 这种理解将帮助您为Java领域中与String相关的要求做好准备。