Why does numpy std() give a different result to matlab std()?
我尝试将matlab代码转换为numpy,并发现numpy与std函数的结果不同。
在MATLAB中
1
2
| std([1,3,4,6])
ans = 2.0817 |
以numpy
1
2
| np.std([1,3,4,6])
1.8027756377319946 |
这正常吗?而我应该如何处理呢?
NumPy函数np.std采用可选参数ddof:"自由度增量"。默认情况下,这是0。将其设置为1以获得MATLAB结果:
1
2
| >>> np.std([1,3,4,6], ddof=1)
2.0816659994661326 |
要添加更多上下文,在计算方差(标准差为平方根)时,通常将其除以我们拥有的值的数量。
但是,如果我们从较大的分布中随机选择N个元素的样本并计算方差,则将N除以会导致实际方差的低估。为了解决这个问题,我们可以将除以(自由度)的数字降低到小于N(通常是N-1)的数字。 ddof参数允许我们按指定的数量更改除数。
除非另有说明,否则NumPy将计算方差(ddof=0除以N)的有偏估计量。如果要使用整个分布(而不是从较大的分布中随机选择的值的子集),这就是您想要的。如果给出了ddof参数,则NumPy会除以N - ddof。
MATLAB std的默认行为是通过除以N-1来校正样本方差的偏差。这消除了标准偏差中的某些(但可能不是全部)偏差。如果您是在较大分布的随机样本上使用该函数,则可能正是您想要的。
@hbaderts的不错回答给出了进一步的数学细节。
- 我将在Matlab中添加std([1 3 4 6],1)等效于NumPy的默认np.std([1,3,4,6])。所有这些在Matlab和NumPy的文档中都已清楚解释,因此,我强烈建议OP将来一定要阅读这些内容。
-
在某些时候,此标准已更改:np.std()= np.std(ddof = 1),即使文档说np.std()应该默认为ddof = 0 ...
标准偏差是方差的平方根。随机变量X的方差定义为
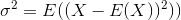
方差的估算器因此为
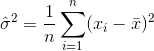 ,可以证明该估计量不收敛到实际方差,而是收敛到
,可以证明该估计量不收敛到实际方差,而是收敛到
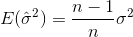 也称为贝塞尔校正。
也称为贝塞尔校正。
现在默认情况下,MATLABs std使用校正项N-1计算无偏估计量。但是,NumPy(如@ajcr所述)默认情况下计算不带校正项的有偏估计量。参数ddof允许设置任何校正项n-ddof。通过将其设置为1,您将获得与MATLAB中相同的结果。
类似地,MATLAB允许添加第二个参数w,该参数指定"称重方案"。默认值w=0导致校正项N-1(无偏估计量),而对于w=1,仅n被用作校正项(有偏估计量)。
-
在校正后的估算器的公式中,不应存在因数n(在总和内)。
-
方差中n-1项背后的直觉:您已经使用样本来估计将用于近似方差的均值。这引入了相关性,因此ddof必须为1。
-
@Frunobulax我已修正了后代的错字。原始等式中发生的是总和的上限未正确显示。而不是n放在求和符号的顶部,而是放在求和内。
对于不擅长统计的人们,一个简单的指南是:
样本中包含DDOF,以抵消可能出现在数字中的偏差。
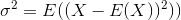
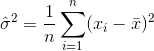 ,可以证明该估计量不收敛到实际方差,而是收敛到
,可以证明该估计量不收敛到实际方差,而是收敛到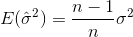 也称为贝塞尔校正。
也称为贝塞尔校正。